Introduction One of the challenges in Meshing is to determine how to store previous data in a database. How many reads and writes need to be carried out is important, as this will have a direct impact upon performance. I’ll document some of my ideas here, mainly to solidify my understanding of it – and […]
24.Sep.2011
What is this about? Several of my blog posts are about Meshing, a P2P database layer for sharing structured data across the Internet. At the time of writing it is in a design and early implementation phase, and to guide the new reader, I’ve added this page. I’ll update it as time goes on, to […]
21.Sep.2011
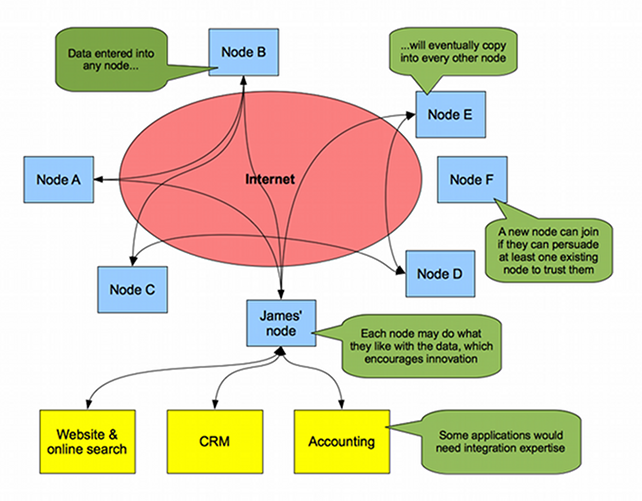
To help illustrate my P2P database proposal, this article looks at three use cases in some detail: a recruitment agency network, a no-agencies jobs network, and building a large dataset of public transport routes.
31.Aug.2011
This article sets out some technical concepts for my peer-to-peer database proposal, and suggests that PHP plus a decent ORM (such as Propel) would be a good, easy-to-deploy platform, with modest hosting requirements. I briefly look at peer trust, data transfer, versioning and how to keep the network balanced.
28.Aug.2011
I present a proposal for an open source software package that permits individuals to create and maintain cheap, distributed, de-centralised, crowd-sourced, scalable, relational databases. I explain why I think this would be useful, and briefly explore some possible use cases.